
In the post, SSAS Multidimensional Best Practices Series – Part I – Introduction we covered the different flavors of analysis available with the recent releases of Microsoft Office and SQL Server. Part II, discussed the various aspects of a typical business intelligence system architecture, performance, and the SSAS internal engine. In this post, we will cover some of the best practices to consider when developing or working with the relational dimensional model database.
Relational Data Source Design
No amount of query tuning and optimization can beat the benefits of a well-designed data model. In general, good relational dimensional model for SSAS follows Kimball modeling techniques.
Cubes are typically built on top of relational data sources that serve as data marts. Through the design surface of SSAS permits the creation of data abstractions on top of the relational source. Computed columns and named queries are examples of this. This can allow for fast prototyping and also may enable the cube designer to correct poor relational design when you as the cube developer are not in control of the design and architecture of the underlying data source.
However, this is not a panacea (cure all)! A well-designed relational data source can make queries and processing of a cube faster. This cannot be stressed enough! If you have a poor dimensional design on the relational dimensional model (a.k.a – data warehouse/data mart) it will only exponentially reveal its ugliness in the OLAP layer as your cube(s) usage and size grows.
Widely Debated
It is widely debated what the most efficient modeling technique is for reporting and analytics: star schema, snowflake schema, or even a third to fifth normal form or data vault models. All are considered by data warehouse designers as candidates.
SSAS Multidimensional..is a Dimensional Model
Analysis Services Multidimensional or Unified Dimensional Model (UDM) is a dimensional model, with some features (reference dimensions) that support snowflakes and many-to-many. No matter which modeling technique is chosen and implemented, performance of the relational model boils down to one simple fact: joins are expensive! This is also partially true for the SSAS engine. For example, if a snowflake is implemented as a non-materialized reference dimension, users will wait longer for queries, because the joins are done at run time inside the Analysis Services engine.
The largest impact of snowflakes occurs during the processing of partition data. For example, if you implement a fact table as a join of two large tables instead of storing them as pre-joined values, processing of the facts will take longer because the relational engine has to compute the join.
Highly Normalized – Be Prepared to Pay the Price
It is possible to build an Analysis Services cube on top of a highly normalized model, but be prepared to pay the price of joins when accessing the relational model. In most cases, that price will be paid a cube processing time. In MOLAP data models, materialized reference dimensions help store the result of joined tables to disk and provide high speed queries even on normalized data. However, if you are using ROLAP partitions, queries will take longer because they are executed at run time. It is likely in this scenario the user query response times will suffer if you are unable to resist the urge of using highly normalized relational models.
Consider Moving Calculations to the Relational Engine
Sometimes calculations can be moved to the relational engine and processed as simple aggregates resulting in much better performance. There is no single solution regarding this, but if you are experiencing performance issues, consider whether the calculation can be resolved in the source database or data source view (DSV) and pre-populated, rather than evaluated at query time.
Use Views – Provide an Abstraction Layer
It is generally a good idea to build your UDM on top of database views. This provides an abstraction layer on top of the physical, relational model. If a cube is built on top of views, the relational database can still be modified to some degree without breaking the cube. However, the exception is if you make changes to something cube is currently referencing without updating the SSAS solution the cube will not successfully process.
Use Views – Query Binding Dimensions
Query binding can be implemented with the use of views (instead of tables) for the underlying dimension data source. This permits the use of query hints, indexed views, or other relational database tuning techniques to optimize the SQL statement that accesses the dimension table through the view. This also can allow to turn a snowflake design in the relational source into a UDM that is a pure star schema.
Use Views – Processing Through Views
Depending on the relational source, views can often provide a means to optimize the behavior of the relational database. One best practice in terms of SSAS, is to use the NOLOCK query hint in the view definition to remove the overhead of locking rows on a table as the view is scanned. Now depending on your processing strategy you will have to balance the possibility of dirty reads. Using the NOLOCK query hint is only suggested if you are performing batch processing. Views can also be leveraged to pre-aggregate large fact tables with the use of the GROUP BY clause.
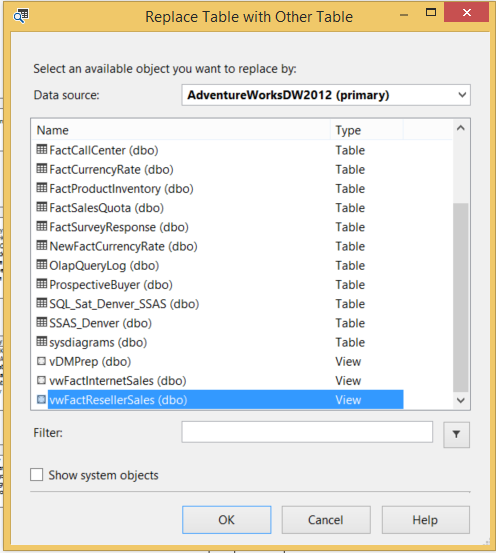
If you need to replace tables in the DSV with the new views you have created, this is a rather straight forward task. However, you will want to make sure that the view does in fact match the previous table definition to avoid any potential processing errors or missing columns (measure and/or dimension keys). To replace the tables with views, simply right click on the table you wish to replace, select Replace Table, then select With Other Table.
You can now select the newly created view to replace the table in the DSV.
Leave a Reply