
Advanced Data Integration in a Modern Day Data Warehouse
In recent surveys by TDWI Research, roughly half of respondents report that they will replace their primary data warehouse (DW) platform and/or analytic tools within three years. Ripping out and replacing a DW or analytics platform is expensive for IT budgets and intrusive for business users.
This raises the following questions:
- What circumstances would lead so many people down such a dramatic path?
- How does data move and integrate in the new/modern day data warehouse?
- How do we take this data and make sure it gets where it needs to go, cleanly, quickly, and efficiently?
- How does the cloud work within our existing and new processes?
- How do we integrate new types of data and what does that mean?
It’s because many organizations need a more modern DW platform to address a number of new and future business and technology requirements. Most of the new requirements relate to big data and advanced analytics, so the data warehouse of the future must support these in multiple ways. Hence, a leading goal of the modern data warehouse is to enable more and bigger data management solutions and analytic applications, which in turn helps the organization automate more business processes, operate closer to real time, and through analytics learn valuable new facts about business operations, customers, products, and so on.
Users facing new and future requirements for big data, analytics, and real-time operation need to start planning today for the data warehouse of the future.
Traditional Data Integration
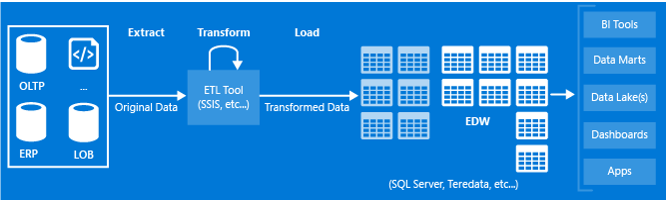
Traditionally, data integration projects have revolved around creating Extract-Transform-Load (ETL) processes that extract data from various data sources within an organization, transform the data to conform to the target schema of an Enterprise Data Warehouse (EDW), and load the data into an EDW as shown in the image. The EDW is then accessed as the single source of truth for BI analytics solutions.
As we can see in the high level architecture shown, mostly structured data is involved and is used for Reporting and Analytics purposes. Although there may be one or more unstructured sources involved, often those contribute to a very small portion of the overall data and hence are not represented in the above diagram for simplicity.
The Traditional Data Warehouse
The traditional data warehouse was designed specifically to be a central repository for all data in a company. Disparate data from transactional systems, ERP, CRM, and LOB applications could be cleansed—that is, extracted, transformed, and loaded (ETL)—into the warehouse within an overall relational schema. The predictable data structure and quality optimized processing and reporting. However, preparing queries was/is largely IT-supported and based on scheduled batch processing.
However, in the case of Big Data architecture, there are various sources involved, each of which is comes in at different intervals, in different formats, and in different volumes.
Challenges to the Data Integrator
Key Trends Breaking the Traditional Data Warehouse
Together, four key trends in the business environment are putting the traditional data warehouse under pressure. Largely because of these trends, IT professionals are evaluating ways to evolve their traditional data warehouses to meet the changing needs of the business. The trends—increasing data volumes, real-time data, new sources and types of data, and cloud-born data.
Increasing Data Volumes
The traditional data warehouse was built on symmetric multi-processing (SMP) technology. With SMP, adding more capacity involved procuring larger, more powerful hardware and then loading the prior data warehouse into it. This was necessary because as the warehouse approached capacity, its architecture experienced performance issues at a scale where there was no way to add incremental processor power or enable synchronization of the cache between processors.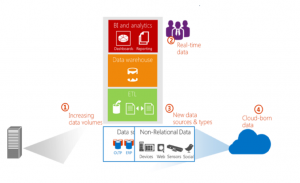
Real-Time Data
The traditional data warehouse was designed to store and analyze historical information on the assumption that data would be captured now and analyzed later. System architectures focused on scaling relational data up with larger hardware and processing to an operations schedule based on sanitized data.
Yet the velocity of how data is captured, processed, and used is increasing. Companies are using real-time data to change, build, or optimize their businesses as well as to sell, transact, and engage in dynamic, event-driven processes like market trading. The traditional data warehouse simply was not architected to support near real-time transactions or event processing, resulting in decreased performance and slower time-to-value.
New Sources and Types of Data
The traditional data warehouse was built on a strategy of well-structured, sanitized and trusted repository. Yet, today more than 85 percent of data volume comes from a variety of new data types proliferating from mobile and social channels, scanners, sensors, RFID tags, devices, feeds, and other sources outside the business. These data types do not easily fit the business schema model and may not be cost effective to ETL into the relational data warehouse.
Yet, these new types of data have the potential to enhance business operations. For example, a shipping company might use fuel and weight sensors with GPS, traffic, and weather feeds to optimize shipping routes or fleet usage.
Companies are responding to growing non-relational data by implementing separate Apache Hadoop data environments, which require companies to adopt a new ecosystem with new languages, steep learning curves and a separate infrastructure.
Cloud-born Data
An increasing share of the new data is “cloud-born,” such as clickstreams, videos, social feeds, GPS, market, weather, and traffic information. In addition, the prominent trend of moving core business applications like messaging, CRM, and ERP to cloud-based platforms is also growing the amount of cloud-born relational business data. Simply stated, cloud-born data is changing business and IT strategies about where data should be accessed, analyzed, used, and stored.
Today’s Data Landscape
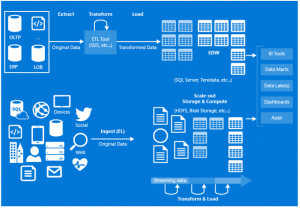 Today’s data landscape for enterprises continues to grow exponentially in volume, variety, and complexity. It is more diverse than ever with on-premises and cloud-born data of different forms and velocities. Data processing must happen across geographic locations, and includes a combination of open source software, commercial solutions and custom processing services and that are expensive, and hard to integrate and maintain.
Today’s data landscape for enterprises continues to grow exponentially in volume, variety, and complexity. It is more diverse than ever with on-premises and cloud-born data of different forms and velocities. Data processing must happen across geographic locations, and includes a combination of open source software, commercial solutions and custom processing services and that are expensive, and hard to integrate and maintain.
The agility needed to adapt to today’s changing Big Data landscape is an opportunity to merge the traditional EDW with capabilities required for a modern information production system.
The Azure Data Factory service is the composition platform to work across traditional EDWs and the changing data landscape to empower enterprises to leverage all data that is available to them for data-driven decision making.
Azure Data Factory Overview
 Azure Data Factory is a cloud-based data integration service that orchestrates and automates the movement and transformation of data. Just like a manufacturing factory that runs equipment to take raw materials and transform them into finished goods, Data Factory orchestrates existing services that collect raw data and transform it into ready-to-use information.
Azure Data Factory is a cloud-based data integration service that orchestrates and automates the movement and transformation of data. Just like a manufacturing factory that runs equipment to take raw materials and transform them into finished goods, Data Factory orchestrates existing services that collect raw data and transform it into ready-to-use information.
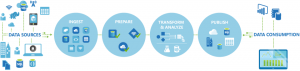
Azure Data Factory works across on-premises and cloud data sources and SaaS to ingest, prepare, transform, analyze, and publish your data. Use Data Factory to compose services into managed data flow pipelines to transform your data using services like Azure HDInsight (Hadoop) and Azure Batch for big data computing needs, and with Azure Machine Learning to operationalize your analytics solutions. Go beyond just a tabular monitoring view, and use the rich visualizations of Data Factory to quickly display the lineage and dependencies between your data pipelines. Monitor all of your data flow pipelines from a single unified view to easily pinpoint issues and setup monitoring alerts. Collect data from many different on-premises data sources, ingest and prepare it, organize and analyze it with a range of transformations, then publish ready-to-use data for consumption.
What Can it Do?
Easily work with diverse data storage and processing systems. Data Factory enables you to use data where it is stored and compose services for storage, processing, and data movement. For example, you can compose information production pipelines to process on-premises data like SQL Server, together with cloud data like Azure SQL Database, Blobs, and Tables.
Transform data into trusted information. Combining and shaping complex data can take more than one try to get right, and changing data models can be costly and time consuming. Using Data Factory you can focus on transformative analytics while the service takes care of the plumbing. Data factory supports Hive, Pig and C# processing, along with key processing features such as automatic Hadoop (HDInsight) cluster management, re-tries for transient failures, configurable timeout policies, and alerting.
Monitor data pipelines in one place. With a diverse data portfolio, it’s important to have a reliable and complete view of your storage, processing, and data movement services. Data Factory helps you quickly assess end-to-end data pipeline health, pinpoint issues, and take corrective action if needed. Visually track data lineage and the relationships between your data across any of your sources. See a full historical accounting of job execution, system health, and dependencies from a single monitoring dashboard
Get rich insights from transformed data Adapt to the constantly changing questions that your organization needs to answer, and stay on top of when your data production is ready to go. Improve your ability to drive better business insights by producing timely and trusted information for consumption. Use data pipelines to deliver transformed data from the cloud to on-premises sources like SQL Server, or keep it in your cloud storage sources for consumption by BI and analytics tools and other applications.
Application Model
There are three information production stages in an Azure Data Factory: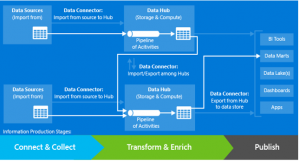
- Connect & Collect. In this stage, data from various data sources is imported into data hubs.
- Transform & Enrich. In this stage, the collected data is processed.
- Publish. In this stage, the data is published so that it can be consumed by BI tools, analytics tools, and other applications.
Data Factories enable developers to create pipelines which are groups of data movement and/or processing activities that accept one or more input data sets and produce one or more output data sets. Pipelines can be executed once or on a flexible range of schedules (hourly, daily, weekly, etc…). A data set is a named view of data. The data being described can vary from simple bytes, semi-structured data like CSV files all the way to tables or models.
Pipelines comprised of data movement activities (for example: Copy Activity) are often used to import/export data from all the data sources (databases, files, SaaS services, etc…) used by the organization into a data hub. Once data is in a hub, pipelines hosted by the compute services of the hub, are used to transform data into a form suitable for consumption (by BI tools, applications, customers, etc.).
Finally, pipelines can be chained (as shown in the diagram) such that the output dataset(s) of one are the input(s) of another. This allows complex data flows to be factored into pipelines that run within a data hub or span multiple hubs. Using pipelines in this way provides organizations the building blocks to compose the best of breed on-premises, cloud and Software-as-a-Service (SaaS) services all through the lens of a single, easily managed data factory.
Azure Data Factory Core Concepts
Azure Data Factory is a fully managed service for composing data storage, processing, and movement services into streamlined, scalable, and reliable data production pipelines.
The Data Factory service consumes, produces, manages and publishes data sets. An Azure subscription may have one or more Azure Data Factory instances. An Azure data factory can be linked to one or more storage or compute services (called Linked Services).
An Azure data factory may have one or more pipelines that process data in linked services by using linked compute services such as Azure HDInsight. An Azure data factory does not contain the data within it. The data is rather stored outside of the data factory, in a user’s existing storage system.
Linked Service
A linked service is a service that is linked to an Azure data factory. A linked service can be one of the following:
A data store such as Azure Storage, Azure SQL Database and on-premises SQL Server database
A compute service such as Azure HDInsight.
A data store is a container of data or data sets and Azure HDInsight is the only compute service supported at this time. You first create a linked service to point to a data store and then define data sets to represent the data from that data store.
Data Set
A named view of data. The data being described can vary from simple bytes, semi-structured data like CSV files all the way up to relational tables or even models. A table is a data set that has a schema and is rectangular.
Pipeline
A pipeline in an Azure data factory processes data in linked storage services by using linked compute services. It contains a sequence of activities where each activity performing a specific processing operation. For example, a Copy activity copies data from a source storage to a destination storage and Hive/Pig activities use a Azure HDInsight cluster to process data using Hive queries or Pig scripts.
Typical steps for creating an Azure Data Factory instance are:
- Create a data factory
- Create a linked service for each data store or compute service
- Create input and output data sets
- Create a pipeline
Azure Data Factory Terminology
Activity
A data processing step in a pipeline that takes one or more input data sets and produces one or more output data sets. Activities run in an execution environment (for example: Azure HDInsight cluster) and read/write data to a data store associated with the Azure Data Factory instance.
Data Hub
An Azure Data Hub is a container for data storage and compute services. For example, a Hadoop cluster with HDFS as storage and Hive/Pig as compute (processing) is a data hub. Similarly, an enterprise data warehouse (EDW) can be modeled as a data hub (database as storage, stored procedures and/or ETL tool as compute services). Pipelines use data stores and run on compute resources in a data hub. Only HDInsight hub is supported at this moment.
The Data Hub allows a data factory to be divided into logical or domain specific groupings, such as the “West US Azure Hub” which manages all of the linked services (data stores and compute) and pipelines focused in the West US data center, or the “Sales EDW Hub” which manages all the linked services and pipelines concerned with populating and processing data for the Sales Enterprise Data Warehouse.
An important characteristic of Hub is that a pipeline runs on a single hub. This means that when defining a pipeline, all of the linked services referenced by tables or activities within that pipeline must have the same hub name as the pipeline itself. If the HubName property is not specified for a linked service, the linked service is placed in the “Default” Hub.
Slice
A table in an Azure data factory is composed of slices over the time axis. The width of a slice is determined by the schedule – hourly/daily. When the schedule is “hourly”, a slice is produced hourly with the start time and end time of a pipeline and so on.
Slices provide the ability for IT Professionals to work with a subset of overall data for a specific time window (for example: the slice that is produced for the duration (hour): 1:00 PM to 2:00 PM). They can also view all the downstream data slices for a given time internal and rerun a slice in case of a failure.
The run is a unit of processing for a slice. There could be one or more runs for a slice in case of retries or if you rerun your slice in case of failures. A slice is identified by its start time.
Data Management Gateway
Microsoft Data Management Gateway is software that connects on-premises data sources to cloud services for consumption. You must have at least one gateway installed in your corporate environment and register it with the Azure Data Factory portal before adding on-premises data sources as linked services.
The Modern Data Warehouse – Present and Future
For organizations that need a modern data warehouse that satisfies new and future requirements, these are some of the recommendations that can potentially guide your solution design.
Deploy a modern data warehouse as a foundation for leveraging big data.
In that light, Hadoop and RDBMS-based data warehouses are complementary, despite a bit of overlap. More to the point, the two together empower user organizations to perform a wider range of analytics with a wider range of data types, with unprecedented scale and favorable economics. For these reasons, most modern data warehouses will be built on a foundation consisting of both relational and Hadoop technologies in the near future.
Enabling Technologies:
- RDBMS
- SQL
- Hadoop Distributed File System (HDFS)
- Other Hadoop tools
- MapReduce
- Hive
- HBase
- Other Hadoop tools
Make sense of multi-structured data for new and unique business insights.
In addition to very large data sets, big data can also be an eclectic mix of structured data (relational data), unstructured data (human language text), semi-structured data (RFID, XML), and streaming data (from machines, sensors, Web applications, and social media). The term multi-structured data refers to data sets or data environments that include a mix of these data types and structures.
Enabling Technologies:
- Hadoop
- Natural Language Processing
Implement advanced forms of analytics to enable discovery analytics for big data.
Online analytic processing (OLAP) continues to be the most common form of analytics today. OLAP is not going away due to its value serving a wide range of end users. The current trend is to complement OLAP with advanced forms of analytics based on technologies for data mining, statistics, natural language processing, and SQL-based analytics. These are more suited to exploration and discovery than OLAP is. Note that most DWs today are designed to provide data mostly for standard reports and OLAP, whereas the modern data warehouse will also provide more data and functionality for advanced analytics.
Enabling Technologies:
- RDBMS optimized for SQL-based analytics
- RDBMS integrated with Hadoop
- Other Hadoop tools
- MapReduce
- Hive
- Hbase
- Other Hadoop tools
- Hive ODBC connectivity – Excel
Empower the business to operate in near real time by delivering data faster
Sometimes the term real time literally means that data is fetched, processed, and delivered in seconds or milliseconds after the data is created or altered. However, most so-called real-time data operations take minutes or hours and are more aptly called near real time . That’s fine, because near real time is an improvement over the usual 24-hour data refresh cycle, and few business processes can react in seconds anyway.
Enabling Technologies:
- SQL queries that return results in mix seconds
- Columnar data stores
- In-memory databases
Integrate multiple platforms into a unified data warehouse architecture
For many, a cloud is a solid data management strategy due to its fluid allocation and reapportionment of virtualized system resources, which can enhance the performance and scalability of a data warehouse. However, a cloud can also be an enhancement strategy that uses a hybrid architecture to future-proof data warehouse capabilities. To pursue this strategy, look for cloud-ready, on-premises DW platforms that can integrate with cloud-based data and analytic functionality to extend DW capabilities incrementally over time.
Enabling Technologies:
- RDBMS/HDFS combination
- DW Appliances
- On-prem/Cloud mix
Demand high performance and scalability of all components of a data warehouse
With both traditional enterprise data and new big data exploding exponentially, scalability for data volumes is the top priority for many teams. Other instances of scalability are pressing, too, such as scaling up to thousands of report consumers and regularly refreshing the tens of thousands of reports they depend on.
Enabling Technologies:
- MPP
- Hadoop – HDFS Clusters
Videos Available
In addition to this blog post, there are also video blog posts available to you over on the Video Log page. To view the necessary steps to perform the steps covered in the Create an Azure Data Factory video, it is recommended that you perform the steps performed in the prerequisite steps videos.
Below is the recommended viewing order:
- Prerequisite Video 1 – Azure Data Factory – Create a Azure Blob Storage Account
- Prerequisite Video 2 – Azure Data Factory – Create a Azure SQL Server and Database
- Prerequisite Video 3 – Azure Data Factory – Prepare Azure Blob Storage and Azure SQL Database
- Video 4 – Create Azure Data Factory
Happy Data Integrating!
Leave a Reply